




Big Data
Anotações importantes relativa a disciplina "Big Data,
MBA em Análise de Dados com BI e Big Data" (EAD Unicsul) - Publicado em junho/2020.
REFERÊNCIAS BIBLIOGRÁFICAS:
- Material didático da disciplina;
- Análise da informação para tomada de decisão, desafios e soluções. Curitiba, PR: Intersaberes
- A Practical Approach to Cloud IaaS with IBM SoftLayer - http://www.redbooks.ibm.com/
- Building Big Data and Analytics Solutions in the Cloud - http://www.redbooks.ibm.com/
- Building Real-time Mobile Solutions with MQTT and IBM MessageSight - http://www.redbooks.ibm.com/
Casos de uso emergentes em Big Data
Referência: RedBook IBM “Information Governance Principles and Practices for a Big Data Landscape” - Capítulo 4
As organizações são desafiadas com uma série de considerações, como por exemplo:
- Como gerenciar, usar e analisar os dados quando não estiverem em formato comum, familiar ou em formato pronto para ser utilizado (como em um banco de dados relacional);
- Como usar fontes de dados não tradicionais de clientes (como dados de call center ou comentários de mídia social) para entender melhor e prever o comportamento do cliente;
- Como processar dados sensíveis ao tempo para a tomada de decisões em tempo real, tal como a identificação de riscos de segurança;
- Como usar o range de dados de logs e de sensores para responder a eventos baseados em máquinas, prever o tempo de inatividade ou garantir que os contratos de nível de serviço sejam mantidos;
- Como encontrar e obter dados de alto valor a partir das novas fontes de dados que podem se conectar a fontes tradicionais para obter “insights” aprimorados;
- Como tirar proveito das novas tecnologias para diminuir o custo total de Propriedade (total cost of ownership - TCO), enquanto se obtém o máximo valor de seus dados.
Apesar das diferenças existentes entre os diversos tipos de indústrias, cinco casos de uso primários surgiram em torno desses desafios:
- Exploração dos dados;
- Vista 360° melhorada do cliente;
- Extensões de segurança e inteligência;
- Análise de operações;
- Modernização do Data Warehouse.
Importante ressaltar que esses casos não são mutuamente exclusivos, pois podem ocorrer simultaneamente (ex.: informação de sensores correlacionadas com informações de vendas ou preços, para uma melhor visão e foco em campanhas de marketing, ou identificação de fraudes ou riscos de segurança).
O primeiro passo para o uso de big data é descobrir, acessar e usar o que você tem para suportar tomadas de decisão e tarefas operacionais do dia a dia, sendo este um passo crítico e imperativo para big data.
Logo, explorar os dados é o caminho para começar, mas porque o entendimento e exploração dos dados é tão importante???
- Se você não conhece os dados disponíveis, então não terá como obter valor para nenhum caso de uso;
- Se você não conhece o volume dos dados, então não conseguirá gerenciar o ambiente de forma apropriada;
- Se você não conhece com que frequência os dados chegam ou com que velocidade eles se tornam desatualizados, então não conseguirá tomar decisões no tempo necessário;
- Se você não conhece a variedade de informações, então não saberá como integrá-las ou como relacionar com outras fontes de informações, e não terá como agregar valor;
- Se você não conhece o conteúdo dos dados, então não conhecerá quais riscos estes dados podem apresentar para sua organização, não saberá se decisões ruins foram tomadas e poderá apresentar não conformidades regulatórias.
O crescimento das coletas de dados brutos como de sensores (IoT), logs de máquinas e acessos a web sites é um outro desafio para big data com a questão de como as organizações podem impulsionar análises para tomadas de decisões a partir destas informações.
Identificação do Valor
Explorar dados em Big data se tornou um método para identificar os dados que se possa derivar valor ou lucro versus dados que são armazenados e se tornam “lixo”. Claramente, procurar e encontrar dados de interesse, particularmente ao redor dos diversos repositórios de conteúdo (dados estruturados e não estruturados), é um aspecto chave para explorar os dados, que melhora o acesso à informação, o compartilhamento de conhecimento e a tomada de decisões, além de reduzir trabalhos duplicados. Habilidades básicas como indexar, procurar, descobrir e analisar textos são necessárias para suportar a incorporação de muitas fontes de dados nas organizações.
Capacitação de equipes de ciência de dados
Ciência de dados abrange um range de habilidades como análises estatísticas e modelagens matemáticas, reconhecimento de padrões, técnicas de visualização de dados etc. Cientistas de dados devem estabelecer hipóteses, procurar potenciais fontes de dados relevantes, e aplicar técnicas de análise e modelagem para testar hipóteses. Dados poderão exigir filtros ou sumarizações para serem correlacionados com outras informações, e diferentes modelos, algoritmos e abordagens podem ser necessárias para executar tarefas como análise de séries temporais e análises visuais e de áudio, ou ainda pode ser necessário a aplicação de técnicas de otimização como programação linear ou quadrática.
A exploração dos dados é, portanto, fundamental para trabalhos subsequentes provisionando conhecimento a partir de grande variedade de conteúdo e onde o volume e variedade de dados pode ser efetivamente aplicado, focando em tarefas chaves como:
- Identificar fontes de informação promissoras;
- Identificar características possíveis para uso e relacioná-las com fontes de informação existentes;
- Validar hipóteses ou encontrar correlações para gerar hipóteses (por exemplo, nevascas diminuem as vendas em lojas, mas aumentam as vendas online);
- Encontrar características e riscos do ponto de vista de governança;
- Determinar se alguma fonte de dados deve ser operacionalizada (e retida).
Refere-se aos esforços de big data para um entendimento do que o consumidor precisa, e antecipar o seu comportamento. Um amplo conhecimento do comportamento do cliente com questionamentos como porque ele compra, como ele prefere comprar, qual será a próxima compra, quais fatores o leva a recomendar companhias para outras pessoas, o que ele não gosta etc., permitem um amplo conhecimento do consumidor, suas necessidades e futuros comportamentos.
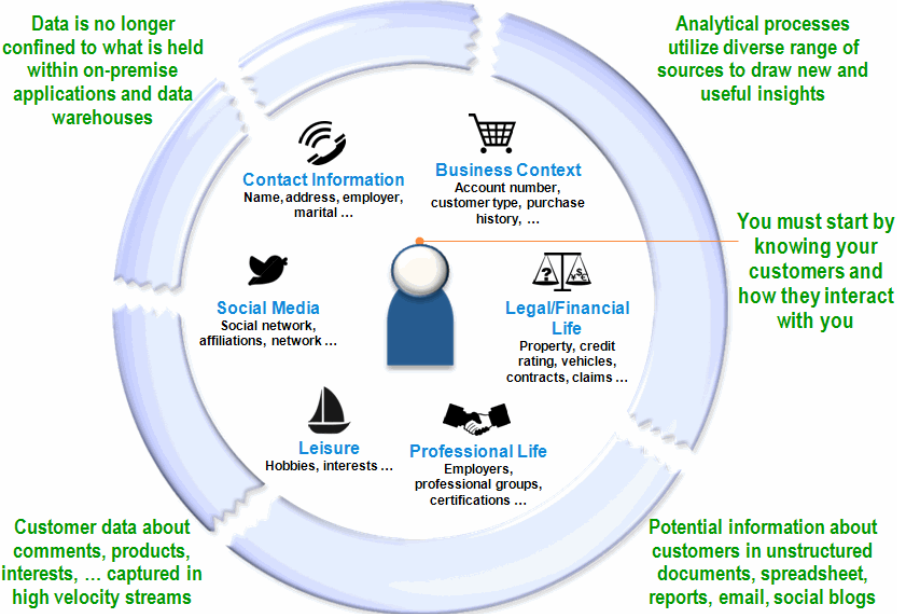
ibm.com/redbooks - "Information Governance Principles and Practices for a Big Data Landscape" - Figure 4-2
Esse princípio se aplica não apenas no setor de varejo, mas igualmente no setor de telecomunicações, saúde, governo, bancos e finanças e setores de produtos de consumo em que consumidores e cidadãos estão envolvidos, e interações B2B (business-to-business) com parceiros e fornecedores. Já os chamados “likes” podem gerar significativo interesse no que a empresa oferece.
Expandindo o range dos dados relacionados ao cliente
Redes sociais são um exemplo de origem de dados de clientes para big data. Problemas com produtos e serviços podem ser imediatamente expressados e expostos para um grande número de pessoas, o que pode gerar um impacto negativo nas vendas ou suporte ao consumidor, assim como os chamados “likes” podem impactar positivamente.
Entender e segmentar o consumidor através da grande variedades de dados relacionados ao seu comportamento pode suprir o marketing com informações que poderá focar em diferente grupos oportunamente através de ofertas, ações de fidelidade para manter o cliente, além de suprir o suporte com informação para que esse possa atuar rapidamente na solução de problemas.
A visão 360° se estende aos funcionários da linha de frente, provisionando informações para atrair clientes, desenvolver relacionamentos confiáveis etc., informações estas que devem estar disponíveis para navegação rápida e simples propiciando a descoberta do que é necessário para um cliente em específico.
Compromissos com cada cliente de forma personalizada
Um ponto focal para essa visão aprimorada do cliente é o envolvimento com este de forma personalizada ou um entendimento mais abrangente de que cada cliente gera maior receita e menor rotatividade (também chamada taxa de rotatividade – churn rate ou taxa de atrito – attrition rate, representando uma medida da perda de clientes em um período). As organizações esperam que uma visão da experiência pessoal e de forma individual e única, possa colaborar para atingir os vários objetivos, como relacionados a seguir:
- Aumento da receita com a criação de visualizações abrangentes e segmentadas dos comportamentos e preferências dos clientes;
- Aumento da intimidade com o cliente, adicionando análises sociais como uma fonte adicional de informações valiosas sobre a interação com a organização e seus produtos;
- Aumento da satisfação do cliente, com informações mais rápidas e completas da experiência de cada cliente individualmente;
- Melhora da retenção de clientes, prevendo a probabilidade de um cliente desinteressar pela produto ou serviço quase em tempo real;
- Aumento da aceitação de ofertas, analisando o uso e a resposta do cliente a ofertas em tempo real.
Gerenciamento de Campanhas de Micro-Mercado
As organizações descobrem cada vez mais que as mensagens direcionadas aos micro-mercados (pequenos segmentos de sua base de clientes) alcançam retornos mais altos do que as amplas campanhas de marketing generalizadas. Para fazer isso de maneira eficaz, as organizações devem realizar as seguintes tarefas:
- Capturar e analisar o sentimento e afinidade do consumidor pela marca e produto;
- Identificar e gerar afinidade de marca e produto;
- Enriquecer os dados dos clientes com conteúdo a partir de e-mail para diferenciar as ofertas de serviços e produtos;
- Melhorar o retorno dos gastos em marketing com ofertas e promoções personalizadas;
- Otimizar ofertas para melhorar a média de compras por consumidor;
- Analisar o sentimento em redes sociais para avaliar o resultado de campanhas;
Retenção do cliente
Outro objetivo da visão 360º é a melhora da retenção do cliente baseando-se também em comportamentos que podem ser verificados nas variadas fontes de dados, e não apenas avaliando transações feitas. Vale reforçar as inúmeras fontes de dados disponíveis atualmente, como dados de call center, e-mails, redes sociais etc.
Previsão de demanda em tempo real
Com a previsão de demanda em tempo real, pode-se otimizar o estoque na produção e varejo de forma eficiente. Ao utilizar big data, analisando fontes como mídia social, previsões meteorológicas, tendências emergentes etc., podem ser identificadas demandas em tempo real e quando necessário aumentar a produção e estoque. Vale relacionar algumas formas de prever a demanda:
- Através de padrões históricos de vendas e preços por loja, cadeia, produto, categoria;
- Informações sobre sentimentos locais para entender tendências localizadas;
- Informações meteorológicas ou de notícias que podem se correlacionar ou desencadear uma demanda maior para mercadorias específicas (por exemplo, pás devido a aproximação de tempestades de neve, ou placas de madeira compensada para furacões iminentes);
Ao mesmo tempo em que as organizações estão tentando melhorar a compreensão de seus clientes, elas também estão envolvidas na identificação e prevenção de ameaças à sua segurança, e manter os dados em segurança é crítico. Violações de dados não apenas custam dinheiro, elas também podem reduzir os preços das ações e causar danos irreparáveis à marca. Proteger a reputação preservando a marca e mantendo a confiança do cliente estão entre os principais objetivos organizacionais, além de ser requerido por lei.
Melhora da segurança tradicional através de “analytics”
Para identificar e se proteger contra ameaças, as organizações devem aprimorar as soluções de segurança para evitar crimes, analisando todos os tipos e fontes de dados disponíveis (não estruturado e streaming), melhorando também o uso de fontes de dados subutilizadas, e consequentemente melhorando a inteligência, informações sobre segurança e aplicação da lei. Para combater essas ameaças sofisticadas, as organizações devem adotar abordagens que ajudem a detectar anomalias e indicadores sutis de ataque. Para fazer isso, é necessário coletar e analisar dados da infraestrutura de segurança, incluindo dados tradicionais de log e eventos e dados de fluxo de rede, informações de configuração e vulnerabilidade, e muito mais. Em suma, a segurança se tornou um grande problema de dados. Os tipos de análise que as plataformas de big data fornecem geralmente usam base históricas, estatísticas e visualizações para descobrir evidências de fraudes ou violações de segurança. A seguir alguns exemplos:
- Correlacionar milhões de solicitações DNS globais, transações HTTP e informações completas de pacotes para identificar comunicações maliciosas associadas a robôs (botnets);
- Descobrir fraudes correlacionando atividades históricas e em tempo real da conta e usando linhas de base para detectar comportamentos anormais do usuário e transações suspeitas;
- Análise linguística e preditiva para analisar o e-mail e as redes sociais e identificar atividades suspeitas, acionando medidas proativas antes que um incidente ocorra.
Finalmente, vale observar alguns pontos chaves relativos à segurança, incluindo tarefas como as relacionadas a seguir:
- Analisar dados de fontes existentes e novas (dados em movimento e em repouso) para encontrar padrões e associações;
- Analisar dados gerados continuamente, como vídeo, áudio e dispositivos inteligentes;
- Incorporar atualizações a informações de inteligência em tempo real;
- Prever, detectar e atuar sobre as ameaças à segurança da rede mais rapidamente;
- Usar dados de redes sociais para rastrear atividades criminosas em tempo real e ao longo do tempo.
Predição e prevenção de problemas de rede
Todas as organizações estão vulneráveis a ocorrência de problemas em suas redes de computadores, tanto interno quanto externos. Cyber ataques são os problemas mais comumente reportados, mas eles são apenas um dos problemas externos possíveis, que podem incluir malware (softwares infectados por vírus) ou qualquer outro tipo de ação com a intenção de desabilitar ou interromper a operação de uma empresa. Outro problema externo emergente é o chamado “hacktivism” (ativismo social através de “hacking”) com o objetivo de protestar contra práticas de uma corporação. Problemas internos são outro tipo de preocupação, com diversos motivos possíveis, que vão desde imperícia e falta de investimentos até atuações maliciosas e baseadas em ganhos ilícitos, como venda de propriedade intelectual ou lista de clientes, e algumas vezes até dados de funcionários. O impacto de um incidente cibernético dentro de uma organização pode ser grande, afetando a produtividade (horas perdidas) e o desempenho financeiro (vendas perdidas, classificação de crédito e preço das ações), incorrendo em custos adicionais (horas extras e multas regulatórias) e custos ocultos (passivos e oportunidades perdidas), além de comprometer a reputação de uma organização. Para uma melhor análise preditiva faz-se necessário uma ampla combinação de dados, observando detalhes como:
- Rede com alto volume de eventos DNS;
- Padrões históricos de acesso e uso por usuários;
- Registros históricos de como as infecções por malware se espalharam ou os caminhos de rede que foram usados em ataques anteriores;
- E-mail, repositórios de documentos e a movimentação de dados pela rede;
- Redes sociais, privilégios de acesso e outros dados que criam pontos de alto risco;
- Relatórios de recursos humanos, feeds de notícias e análises de funcionários para possíveis ameaças internas;
- Feeds de mídia social, feeds de notícias e relatórios do governo que podem apontar riscos de hacktivismo.
Visão ampliada da vigilância
Alguns riscos de segurança assumem uma forma física, tendo como exemplo atividades criminosas dirigidas a indivíduos. Nas empresas, compreendendo as situações físicas, por exemplo, através de dados tirados de câmeras ou até fotos que são carregadas na Internet, pode-se reduzir fraudes. Logo, mídia de vigilância, (vídeo e áudio, fontes internas ou externas) são importantes aliados para alcançar uma maior compreensão sobre estes riscos físicos. Observar que um equipamento de vídeo e áudio produz um enorme e constante volume através de streaming de informações (para este tipo de solução, fala-se na magnitude de processamento de 275 MB de dados de “n” sensores em um décimo quarto de um segundo). A vigilância pode ainda ser aprimorada usando fontes de informação mais amplas e de vários tipos:
- Coleta e processamento de dados da máquina (internet, satélite, vídeo e áudio);
- Análise de dados não estruturados, correlação e correspondência de padrões;
- Sistemas de vigilância de segurança implantados para detectar, classificar, localizar e rastrear ameaças em potencial em locais altamente sensíveis;
Predição de crimes
Além das informações tradicionais, as organizações procuram trazer novas fontes de informação significativas para rastrear criminosos em tempo real para prever e prevenir crimes. Exemplos para essas fontes são:
- Canais de comunicação de mídia móvel e social;
- Análise linguística e de identidade de fontes de texto e voz;
- Informações consolidadas sobre criminosos, prisões, pedidos de assistência (911), recursos humanos e informações geográficas de vários canais;
- Informações históricas sobre benefícios e direitos dos suspeitos.
A análise de operações de forma geral se concentra no melhor uso dos dados de máquina. Os dados da máquina são frequentemente associados a logs ou dados de sensores, sendo esses certamente parte do domínio de dados da máquina, mas trata-se de uma área muito mais ampla. Dados da máquina são qualquer informação que foi criada automaticamente a partir de um processo, aplicativo, computador ou qualquer tipo de máquina sem a intervenção de um ser humano:
- Logs de sistema ou aplicativo;
- Leituras do sensor;
- Medições automatizadas;
- Sinais de GPS (por exemplo, de telefones celulares ou dispositivos de rastreamento).
- Dados de registros de chamadas;
- Dados de configuração de dispositivos;
- Dados de mensagens de transações de APIs;
- Dados sobre navegação em websites;
- Dados sobre pacotes de rede etc.

e atividades associadas a análise destes dados
ibm.com/redbooks - "Information Governance Principles and Practices for a Big Data Landscape" - Figure 4-3
Cada dado de máquina tem o seu formato específico para o dado “bruto” (“raw format”), e usualmente as organizações não conseguem usar essa grande quantidade de dados que é gerada. Dados de máquina usualmente tem os seguintes atributos:
- Crescem em taxas exponenciais;
- Chegam em grandes volumes e em grande variedade de formatos, usualmente sem nenhum tipo de padronização;
- Chegam em diferentes intervalos de tempo (diferentes granularidades);
- Necessitam ser combinadas com dados existentes, como por exemplo dados cadastrais;
- Necessitam de análises complexas e ser correlacionadas com diferentes tipos de dados;
- Requerem recursos exclusivos de visualização baseados no tipo de dados e no setor/aplicativo;
Um exemplo típico são as áreas operacionais e de planejamento de operadoras de telefonia móvel, com grande quantidade de equipamentos para compor a infraestrutura necessária. Observe a topologia de rede apresentada a seguir:
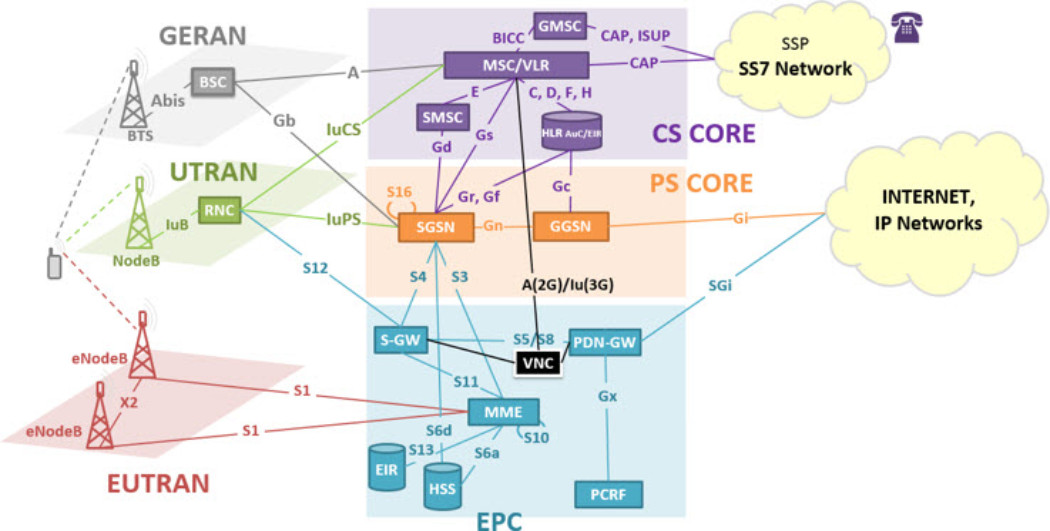
Cada bloco é composto por um ou vários equipamentos, porém para exemplificar vamos focar somente nas estações rádio base que costumamos ver espalhadas pelas cidades nas torres de telefonia celular, representadas no diagrama pelos elementos BTS (2G), NodeB (3G) e eNodeB (4G), localizados mais a esquerda no diagrama acima.
Na tabela a seguir temos uma projeção de volumetria de dados na magnitude de 390 GBytes diários para uma estimativa com subutilização de dados disponíveis, pois cada vendor disponibiliza milhares de contadores, porém estamos considerando apenas um número necessário para no mínimo acompanhar a qualidade da rede, além de se tratar apenas um grupo pequeno de dados que possibilita a geração de KPIs diversos (taxas de queda ou de sucesso de conexões de voz ou dados, tráfego cursado de voz e dados, número de usuários conectados etc.), observando que temos ainda dados relacionados a alarmística, configuração e arametrização dos equipamentos, inventário dos equipamentos etc. Logo não é absurdo pensar na magnitude de TBytes/dia apenas para este pequeno grupo de equipamentos na operadora.
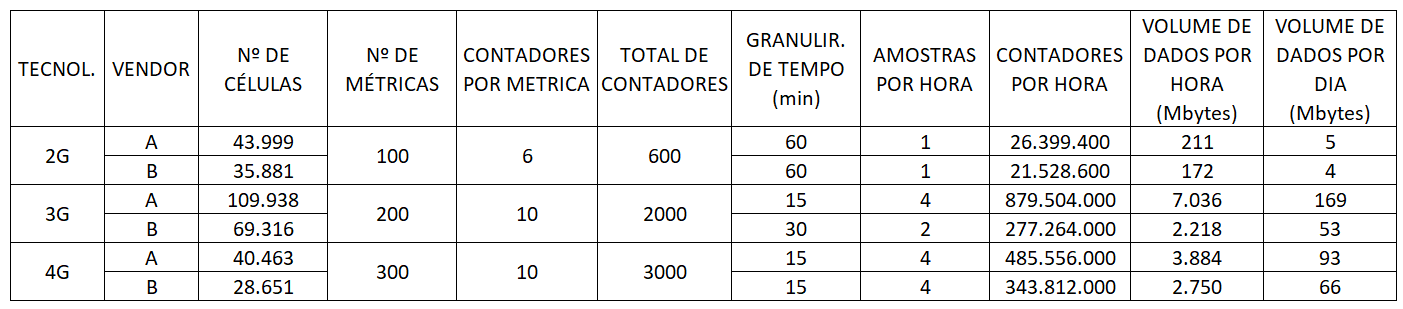
Oservação: estes números são baseados em um estudo de caso para uma operadora com atendimento nacional, dados relativos a 2018.
A partir dos dados apresentados vamos então contextualizar o que foi descrito anteriormente como atributos de dados de máquina:
- Quanto aos tipos de dados temos caracterizadas medições automatizadas com dados de registros de contadores de eventos (observar que não se refere aos CDRs, conhecidos bilhetes, que são gerados por chamada de voz ou de dados, e de complexidade e volumetria muito maior);
- São dados que crescem em taxas exponenciais à medida que as redes necessitam ser ampliadas com frequência para atender requisitos de cobertura ou qualidade. Com a evolução tecnológica esse volume também cresce, visto que ficam mais complexas e fornecem mais dados (observar na tabela o crescimento do volume para as tecnologias 3G e 4G);
- São dados que chegam em grandes volumes conforme números apresentados, e em grande variedade de formatos (texto com formato proprietário, csv, xml etc. e diferente para cada fornecedor), e usualmente sem nenhum tipo de padronização, observando ainda que no exemplo existem dois fornecedores cujos os dados são fornecidos em formatos e granularidades distintas, tornando ainda mais complexa a tarefa de uniformização de métricas;
- São dados que chegam em diferentes intervalos de tempo (15, 30 e 60 minutos no exemplo);
- São dados que necessitam ser combinados com dados existentes, como por exemplo dados cadastrais para gerar KPIs regionais;
- Necessitam de análises complexas e ser correlacionadas com diferentes tipos de dados, tendo como exemplo a correlação entre KPIs e dados de configuração e parametrização de equipamentos para verificar resultados de trabalhos de otimização.
Observa-se então que áreas operacionais tiram proveito das tecnologias de big data para analisar os grandes volumes desses dados de máquinas multi-estruturados, e então gerar informações a partir deles, usando uma ampla variedade de recursos analíticos para obter melhores resultados de negócios.
As organizações podem então executar as seguintes ações:
- Analisar dados de máquina para identificar eventos de interesse;
- Aplicar modelos preditivos para identificar possíveis anomalias;
- Combinar informações para entender a qualidade do serviço;
- Monitorar sistemas para evitar a degradação ou interrupções do serviço.
Existe então uma grande variedade de cenários aplicáveis a este caso de uso, alguns serão comentados a seguir.
Gerenciamento de tráfego
Curiosamente, quando falamos em gerenciamento de tráfego, a afirmativa é válida tanto para tráfego terrestre e aéreo, quanto para tráfego de redes.
No mundo dos dados e redes de telecomunicações, informações são coletados em tempo real, por exemplo em roteadores e switches de rede, logs de aplicativos e sistemas, monitores de processamento e canais de I/O, tempos de resposta nas interfaces do usuário e filas de mensagens. Algumas dessas informações podem ajudar a analisar ameaças à segurança, outras podem identificar gargalos importantes que podem causar atrasos no processamento e tempo de inatividade para clientes ou funcionários. Mais uma vez, a previsão de possíveis falhas ou picos consistentes no tráfego de rede, permite que operadores e administradores tomem medidas corretivas antes que as falhas afetem as operações comerciais.
Referindo-se ao mundo físico, dados de câmeras que monitoram o trânsito, GPSs em ônibus, taxis, caminhões e usuários através de smartphones utilizando serviços comunitário de navegação como o Waze, informações de voo de linhas aéreas e informações climáticas podem ser combinadas para uma melhor compreensão onde estão os gargalos e fornecer rotas alternativas, rastrear rotas ou verificar se veículos com rotas definidas estão respeitando o trajeto, fornecer informações precisas a passageiros sobre partida e chegada melhorando sua experiência, etc.
Monitoramento e avaliação ambiental
Uma ampla variedade de medidores e sensores vem sendo utilizada em escalas cada vez mais significativas para monitoramento ambiental, com grande variedade de medições como dados físicos, químicos e biológicos, indo desde sensores implantados em rios e represas para avaliar o suprimento de água até os sensores implantados em prédios para melhorar o consumo de energia. Alguns possíveis benefícios, dependendo do setor, são relacionados a seguir:
- Ajudar o gerenciamento de recursos a responder de maneira mais eficaz às mudanças nos recursos hídricos locais. Os usuários podem acessar, agregar, analisar e configurar alertas automatizados usando um portal da web;
- Prever de inundação mais rapidamente e com precisão;
- Identificar e rastrear a poluição e os detritos para aumentar a segurança pública;
- Proporcionar um uso de energia mais eficiente e sem desperdícios etc.
Manutenção preventiva/preditiva
A maioria das indústrias possui equipamentos que requerem manutenção. Os equipamentos podem fazer parte de um complexo processamento de fabricação, podem ser um sistema de aquecimento ou resfriamento de edifícios ou até mesmo sensores e medidores que produzem dados. Identificar e resolver problemas antes que os sistemas falhem economiza tempo, dinheiro e recursos. A análise dos dados da máquina ajuda a alcançar importantes resultados como exemplificado a seguir:
- Otimização trabalhos de campo e redução de custos relacionados ao tempo de inatividade (downtime), mão de obra, manutenção, frequência de reparo e falhas e identificação do problema, através do aumento de disponibilidade e do tempo médio entre as paralisações;
- Diminuição de riscos e operação de maneira ambientalmente consciente e responsável;
- Previsão de qual equipamento tem maior probabilidade de falha e avaliação do potencial custo de cada falha;
- Desenvolvimento de métodos de previsão de falhas que “aprendam” à medida que as condições mudam.
O advento do big data está modificando a visão tradicional do Data Warehouse. A necessidade ou desejo de usar uma variedade maior de dados altera as abordagens de incorporar dados para análises subsequentes.
As organizações devem analisar uma mistura de dados estruturados, não estruturados e de fluxo contínuo que geralmente possuem requisitos de baixa latência (análise em minutos ou horas, não semanas ou meses) e ainda devem suportar consultas e relatórios sobre esses diversos tipos de dados.
Por exemplo, dados brutos podem ser coletados, limpos, transformados e analisados por uma perspectiva operacional. Porém, os dados podem ser necessários para análises adicionais ou suporte a consultas, portanto, após serem transformados em uma forma estruturada ou semiestruturado, os dados podem ser armazenados no Data Warehouse para suporte à decisão, inteligência de negócios ou outras análises adicionais.
Da mesma forma, as organizações estão reconhecendo que há uma riqueza de informações inexploradas em dados abertos de mídia social. No entanto, o Data Warehouse e os bancos de dados relacionais padrão não são adequados para analisar dados de mídia social, pois não são estruturados e requerem diferentes tecnologias para processar e extrair informações úteis.
E provavelmente seja impraticável armazenar todos esses novos dados no próprio Data Warehouse. Esses dados ainda estão mudando rapidamente e possuem uma grande variedade e volume. O tempo necessário para modelar, integrar e implantar esses dados em uma estrutura tradicional, e ainda adquirir o armazenamento necessário para estes volumes, inviabiliza o ambiente clássico do data warehouse. Esse é um problema técnico e financeiro para empresas que tentam usar big data apenas com o data warehouse.
Existem três abordagens diferentes para a modernização do Data Warehouse, como mostrado na figura a seguir:
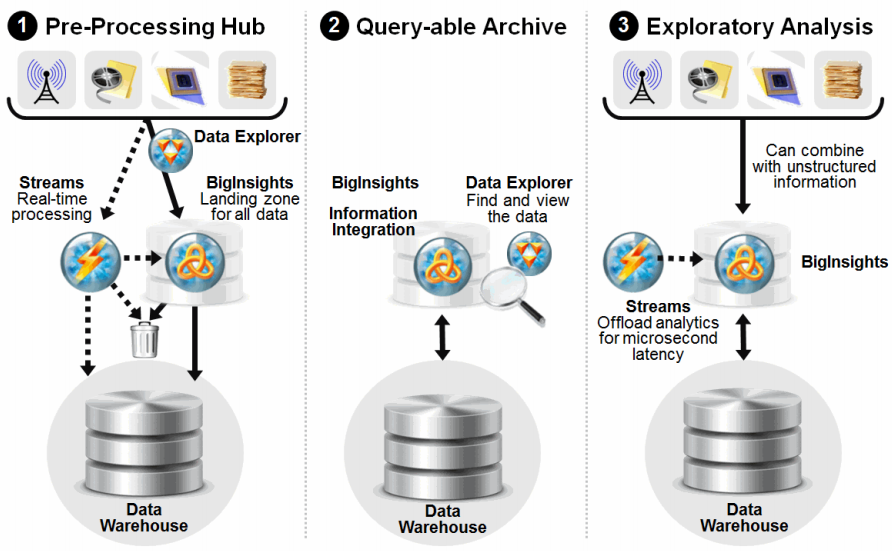
ibm.com/redbooks - "Information Governance Principles and Practices for a Big Data Landscape" - Figure 4-4
Importante salientar que as abordagens adotadas não se limitam a adquirir e armazenar novas fontes de dados.
Cenário 1: Pre-processing hub
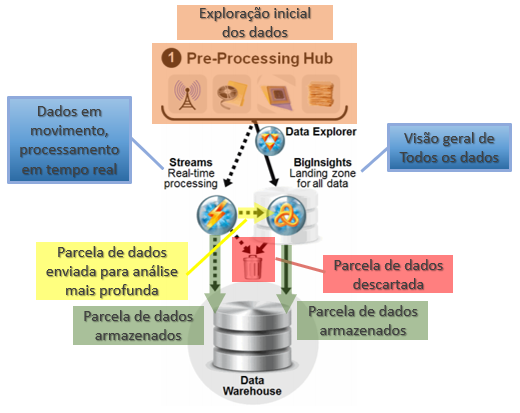
Uma plataforma de pré-processamento trabalha como uma área de triagem e preparação dos dados para determinar quais dados poderiam ser movidos para o data warehouse. Uma exploração inicial pode ser necessária para verificar quais dados devem passar por uma análise mais profunda e quais dados podemos armazenar com um menor custo. Esta etapa não é obrigatória, mas pode ser usada em áreas onde organizações desejam descartar dados. Dados em movimento ou “stream data” também podem ser usados em tempo real através de um componente específico para processar e analisar este tipo de dado, sem ter que armazená-lo antes, para em seguida armazenar somente a parcela de interesse.
A análise de dados em movimento (stream data) também pode ser executada por um componente para esta finalidade, processando e analisando dados de streaming, sem a necessidade de armazená-los primeiro, e determinando quais dados devem ser salvos, seja no HDFS (Hadoop Distributed File System) ou no Data Warehouse. Vale observar que processar e agir sobre as informações à medida que elas estão acontecendo também pode reduzir o volume armazenado no Data Warehouse. Com essa abordagem de área de triagem, os dados podem ser limpos e transformados antes de carregá-los no Data Warehouse.
ibm.com/redbooks - "Information Governance Principles and Practices for a Big Data Landscape" - Adaptado da figura 4-4
Cenário 2: Queryable archive
Nesta abordagem, dados acessados com pouca frequência ou antigos podem ser descartados pelo Data Warehouse ou aplicações de banco de dados usando softwares de integração de informações e outras ferramentas. Os dados descartados podem ainda ser armazenados em banco de dados virtual (“data Federation”) para realização de consultas e relatórios.
“Data Federation” refere-se a uma consolidação virtualmente de dados de fontes múltiplas, que para a visão do usuário parecem ser uma base de dados única. Este processo permite aos usuários acessar os dados de qualquer lugar na corporação, independentemente do seu formato ou vendor, ficando a complexidade do processo transparente ao usuário.
Cenário 3: Exploratory analysis
Nesta abordagem, um componente habilita análises prévias para dados em movimento otimizando o Data Warehouse e permitindo novos tipos de análises. Diferentes tipos de dados podem ser combinados (estruturados, não estruturados e streaming), permitindo análises profundas para prover visões (“insights”) que antes não eram possíveis. O componente para análise de dados em movimento atua também como um filtro para separar informações que tenham alto valor, e que poderão ser armazenadas em banco de dados associado a plataforma de análise prévia (“BigInsights”) e Data Warehouse.
A modernização do Data Warehouse usando tecnologias de big data aumenta seu valor, permitindo que as organizações executem tarefas como exemplificado a seguir:
- Adicionar novas fontes de dados ao Data Warehouse;
- Otimizar o armazenamento;
- Racionalizar os dados permitindo maior simplicidade e menor custo;
- Aumentar o uso de análises nas operações globais;
- Habilitar aplicativos analíticos complexos com consultas mais rápidas;
- Escalar análises preditivas e inteligência de negócios;
- Melhorar os recursos e desempenho para geração de relatórios;
- Melhorar a escalabilidade, reduzindo custos e simplificando a estrutura.
Acima de tudo, esta abordagem permite que as organizações otimizem o uso da infraestrutura do Data Warehouse para suportar os volumes dos dados emergentes e históricos e lidar com a grande variedade de dados atuais sem a necessidade de provisionar recursos para transformação de todas as fontes de dados, permitindo uma grande variedade de consultas, relatórios e análises de forma geral, que podem levar a novas ideias e agregar novos valores.