Big Data
Anotações importantes relativa a disciplina "Big Data,
MBA em Análise de Dados com BI e Big Data" (EAD Unicsul) - Publicado em junho/2020.
REFERÊNCIAS BIBLIOGRÁFICAS:
- Material didático da disciplina;
- Análise da informação para tomada de decisão, desafios e soluções. Curitiba, PR: Intersaberes
- A Practical Approach to Cloud IaaS with IBM SoftLayer - http://www.redbooks.ibm.com/
- Building Big Data and Analytics Solutions in the Cloud - http://www.redbooks.ibm.com/
- Building Real-time Mobile Solutions with MQTT and IBM MessageSight - http://www.redbooks.ibm.com/
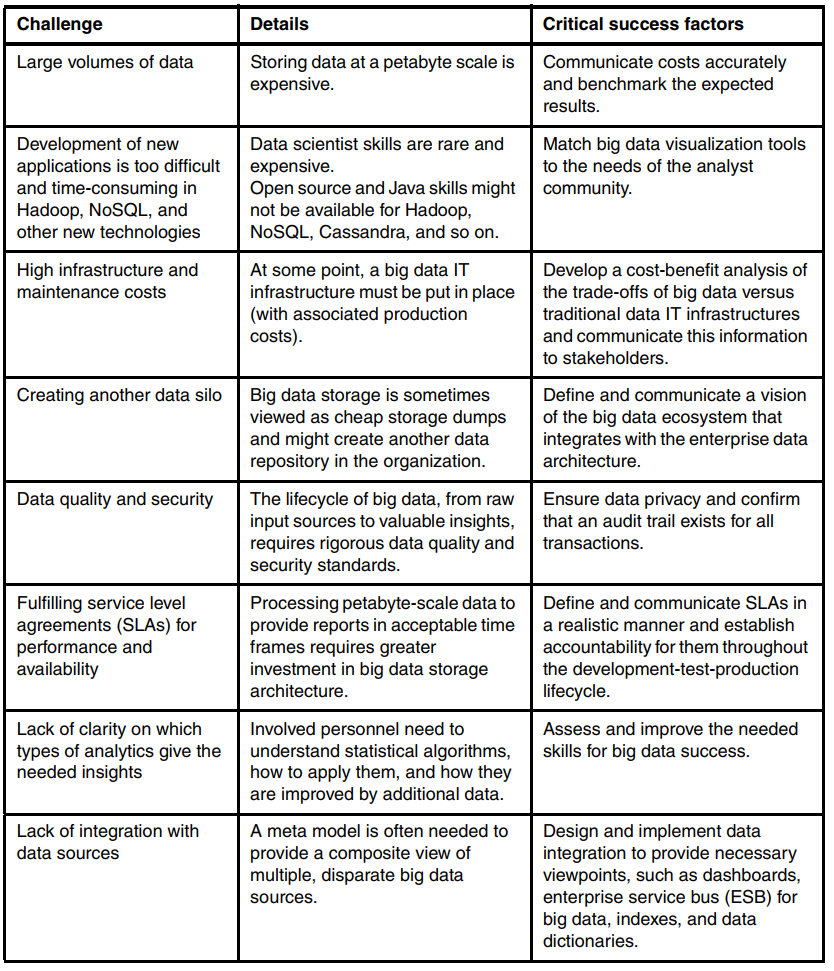
Desafios e oportunidades
Fonte: Análise da informação para tomada de decisão, desafios e soluções. Curitiba, PR: Intersaberes, 2015c. (item 2.4.2.1)
O Modelo relacional (1969) implementado nos principais bancos de dados disponíveis no mercado para tratar apenas dados estruturados, não foi projetado para tratar dados não estruturados, ou suportar uma escalabilidade até a ordem de petabytes (ou mais), tendo seu desempenho fortemente afetado nessas condições. As estruturas tradicionais de indexação e os correspondentes mecanismos de busca e recuperação são inadequados nessas circunstâncias.
Modelos de bancos de dados apropriados ao armazenamento de dados não estruturados, denominados NOSQL (Not only SQL), são projetados para uma escalabilidade compatível com as necessidades do Big Data. No modelo tradicional de mineração de dados, os dados são gerados pelos diversos sistemas transacionais e copiados numa base analítica e atualizada periodicamente (data warehouse) para depois aplicar consultas a essa base com base em dados estáticos, refletindo a realidade de horas ou dias anteriores. Para resolver essa questão, surgiu o conceito de stream processing, um novo paradigma de processamento paralelo no qual, em vez de ocorrer a aplicação de consultas a bases previamente organizadas e estáticas, o fluxo contínuo de dados, ou streaming data, passa por uma série de operações previamente determinadas, sendo exemplo de ferramentas disponíveis no mercado o Haddop e MapReduce.
Hadoop consiste basicamente em uma infraestrutura que permite o processamento massivamente paralelo, utilizando um grande número de computadores (nós), que podem estar em uma mesma rede local, formando um cluster, ou geograficamente distribuidos, constituindo um grid; MapReduce é uma plataforma para o desenvolvimento de aplicações voltadas para o processamento distribuído de grandes volumes de dados, estruturados ou não; Hadoop e MapReduce são projetos originalmente concebidos pela Fundação Apache. Ver Apache Software Foundation (2015a, 20156).
Desafios, riscos e oportunidades que podem ser destacados:
- Interfaces interativas de baixo atrito;
- Técnicas e ferramentas de backup;
- Pessoal qualificado insuficiente;
- Crescimento acelerado de aplicações e surgimento de novas empresas, acirrando a competição tanto por mercados específicos, assim como por mão de obra qualificada;
- Momento histórico de volatilidade tecnológica, com risco de surgimento e rápido desaparecimento de inúmeros produtos e, eventualmente, de suas respectivas empresas;
- Momento de disputa intensa entre as empresas bem-sucedidas com o lançamento de novos produtos, as quais com o tempo deverão ser incorporadas por outras maiores, restando, ao final desse período de maior instabilidade, apenas as empresas que melhor conseguirem se adaptar ao novo cenário tecnológico e econômico.
E de acordo com o IBM RedBooK “Building Big Data and Analytics Solutions in the Cloud”, apesar de big data se tornar cada vez mais popular, é ainda difícil o aproveitamento de todo o seu potencial, devido aos vários desafios técnicos agregados, como exemplificado a seguir:
- Capacidade para armazenar e gerenciar grandes volumes de dados;
- Capacidade para lidar com crescimento acelerado de dados e garantir sua confiabilidade;
- Adoção de métodos para integrar e correlacionar diferentes tipos de dados e usá-los para aplicativos corporativos;
- Adoção de tecnologias massivas de processamento paralelo para processar rapidamente os dados e obter resultados em tempo admissível;
- Aplicação de métodos de extração, transformação e carregamento (ETL) padrões da indústria, qualidade de dados, segurança, “Master Data Management” (MDM) e métodos de gerenciamento do ciclo de vida dos dados.