




Linguagens SQL e NoSQL
Anotações importantes relativa a disciplina "Linguagens SQL e NoSQL,
MBA em Análise de Dados com BI e Big Data" (EAD Unicsul) - Publicado em agosto/2020.
SQL – Structured Query Language
Linguagem padrão utilizado pelos Sistemas de Gerenciamento de Banco de Dados (SGBD) relacionais, permite a criação, alteração e exclusão de tabelas e manipulações de dados. Desenvolvida pelo departamento de pesquisas da IBM como forma de interface para o sistema de banco de dados relacional denominado SYSTEM R (início dos anos 1970), foi originalmente chamada de Structured English Query Language (SEQUEL). Em 1977, foi revisada e passou a ser chamada de Structured Query Language (SQL). Em 1986, o American National Standard Institute (ANSI) publicou um padrão SQL, então a SQL se estabeleceu como linguagem padrão para bancos de dados relacionais. SQL possui comandos para a definição dos dados (DDL – Data Definition Language), comandos para a manipulação de dados (DML – Data Manipulation Language) e uma subclasse de comandos DML, a Data Control Language (DCL), que dispõe de comandos de controle como Grant e Revoke.
Os comandos DDL (Data Definition Language) são compostos por exemplo pelo “create” (destinado à criação do banco de dados, das tabelas que o compõem, além das relações existentes entre as tabelas), “alter” e “drop”. Por meio das instruções DDL, podem ser realizadas as tarefas de:
- Criação, alteração e eliminação de objetos do banco de dados, como por exemplo tabelas, índices, sequências;
- Concessão e revogação de privilégios em objetos;
- Criação do banco de dados;
- Criação de usuários;
- Concessão e revogação de privilégios a usuários.
Os comandos da série DML (Data Manipulation Language) são destinados a consultas, inserções, exclusões e alterações de registros. Como exemplo de comandos da classe DML, pode-se citar os comandos:
- Insert – Inserção de dados;
- Update – Alteração de dados;
- Delete – Remoção de dados;
- Commit – Confirmação das manipulações;
- Rollback – Desistência das manipulações.
Os comandos da série DQL (Data Query Language) servem para fazer a recuperação dos dados. Todas as consultas são executadas através deste tipo de comando, como o “select” (seleciona linhas de dados de tabelas ou visões).
Os comandos da série DCL (Data Control Language) são utilizados para controlar os privilégios de usuários, como:
- permitir a um usuário que se conecte ao banco;
- permitir que crie objetos no banco;
- permitir que consulte objetos do banco; entre outros;
- cancelar os privilégios de um usuário.
Para isso, estão disponíveis as instruções:
- Grant: utilizada para conceder privilégios aos usuários;
- Revoke: utilizada para cancelar os privilégios dos usuários.
Vale observar que na linguagem SQL:
- Não é feita distinção entre maiúsculas de minúsculas, a menos que indicado;
- As instruções SQL podem ser digitadas em uma ou mais linhas;
- As palavras-chave não podem ser divididas entre as linhas nem abreviadas;
- As cláusulas são em geral colocadas em linhas separadas para melhor legibilidade e facilidade de edição;
- As guias e endentações podem ser usadas para tornar o código mais legível. Em geral, as palavras-chave são digitadas em letras maiúsculas, todas as outras palavras, como nomes de tabela e colunas são digitadas em minúsculas;
- Dentro do ambiente SQL*Plus, uma instrução SQL é digitada no prompt SQL e as linhas subsequentes são numeradas, isso é chamado buffer de SQL. Somente uma instrução pode ser a atual a qualquer momento dentro do buffer.
NoSQL – Not Only SQL
Um banco de dados NoSQL é um banco não relacional que não armazena informações no formato relacional tradicional. Não existe um esquema definido para os dados. Os dados são armazenados como pares chave-valor. O termo NoSQL é uma abreviatura de Not Only SQL (Não apenas SQL).
Exemplos de Bancos de Dados NoSQL:
- Oracle NoSQL;
- Cassandra;
- Voldemort;
- MongoDB.
Existem quatro modelos de dados para bancos de dados NoSQL:
- Key-value (Chave-valor): esse é o modelo de dados mais simples para dados não estruturados. É altamente eficiente e altamente flexível. A desvantagem desse modelo é que os dados não são autoexplicativos;
- Columnar (Colunar): esse modelo de dados é bom para conjuntos de dados esparsos, subcolunas agrupadas e colunas agregadas;
- Documento: esse modelo de dados é bom para repositórios XML e objetos autodescreventes. No entanto, o armazenamento nesse modelo pode ser ineficiente;
- Gráfico: este é um modelo relativamente novo que é bom para o relacionamento transversal porém não é eficiente para pesquisas gerais.
Quando devemos utilizar Banco de Dados NoSQL?
- Quando houver a necessidade de grande volume de dados, informações estimadas em petabytes;
- Necessidade de informações em tempo real, ambientes que precisam de tempo de resposta imediato;
- Variedade de dados, sendo um exemplo típico é para um aplicativo que deve ser capaz de armazenar qualquer tipo de informação sobre um paciente (relatórios de raios-x, exames, resultados laboratoriais, insumos médicos, contas médicas etc.);
- Mudança de dados, onde diferentes locais terão políticas diferentes sobre os dados que precisam ser armazenados (essas políticas podem mudar de tempos em tempos).
Como decidir o tipo de tecnologia adequada?
Ao decidir sobre a tecnologia de armazenamento para um aplicativo, você deve considerar dois aspectos principais: os dados a serem armazenados e o esquema do aplicativo:
- Se você tem grandes quantidades de dados de baixa densidade, escassos e de baixo valor a serem armazenados, um banco de dados NoSQL pode ser a melhor escolha;
- Se você tiver dados de alto valor, um RDBMS é uma escolha melhor;
- Se o esquema do aplicativo é dinâmico (ou seja, ele muda constantemente), um banco de dados NoSQL pode ser uma escolha melhor;
- Se o esquema do aplicativo for corrigido, um RDBMS pode ser uma escolha melhor;
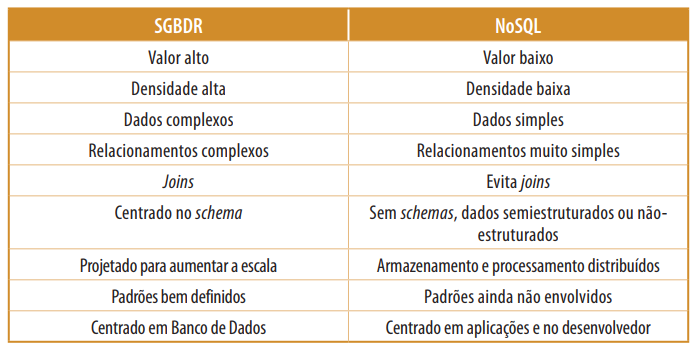
Referência: Tabela 1 – Unidade 3 – Linguagens SQL e NoSQL (Pós UNICSUL)